Cluster
Overview
A Timeplus cluster is composed of nodes, each running the core engine timeplusd. The engine is packaged as a single binary, and its role in the cluster is determined entirely by configuration. Nodes can take on one or more roles: metadata, data, or compute.
Metadata nodes act as the brain of the cluster. They manage cluster topology after node discovery and store critical metadata such as streams, materialized views, tasks, alerts, UDFs, dictionaries, and user credentials etc. In addition, metadata nodes are responsible for essential internal system routines, including automatic load balancing, task scheduling, and alert scheduling. They also maintain internal system streams that provide observability into the cluster’s health and activity.
Data nodes are responsible for managing production data. They handle persistence, replication, and read/write operations, ensuring durability and availability. By default, data nodes are also capable of executing computations, which makes them versatile for both storage and processing workloads.
Compute nodes are specialized nodes dedicated purely to computation. Unlike data nodes, they do not store production data. Instead, they focus on running materialized views, tasks, and alerts etc. Because they are not tied to stored data, compute nodes can be treated as elastic and ephemeral. They are designed to work seamlessly with auto-scaling frameworks such as AWS Auto Scaling Groups or Kubernetes HPA, making them ideal for handling spiky or dynamic workloads.
Each node can be configured with a single role or a combination of roles. For example, in a typical three-node cluster, every node is often configured to serve both as a metadata node and a data node.
Underlying both the metadata and data layers is Timeplus NativeLog, the distributed journal and Write-Ahead Log that powers the cluster. Built on Multi-Raft consensus, NativeLog provides replication, consistency, and reliability as the foundation of Timeplus’s distributed architecture.
The following diagram shows a more advanced cluster design with metadata, data, and compute nodes running on separate tiers.

Distributed Ingest
As explained in the Timeplus Architecture, when data is ingested into a Timeplus stream, it is first appended to NativeLog. In a cluster setup, the data is then replicated to peer replicas using Raft.
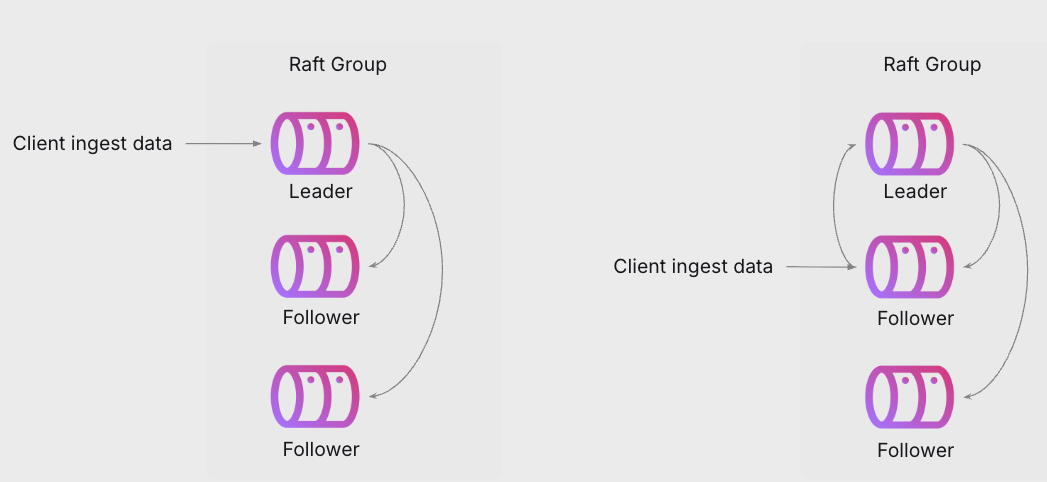
The diagram above shows the ingestion flow with a few possible cases:
-
Ingest to leader replica
- If the ingest lands on the leader replica of a NativeLog shard, the data is appended to the leader’s log.
- The leader then replicates the data to its peer replicas.
-
Ingest to follower replica
- If the ingest lands on a follower replica, the data is first forwarded to the leader.
- The leader then replicates it to the peer replicas.
- This route is slower, so internally the system optimizes ingestion to stick to the leader whenever possible.
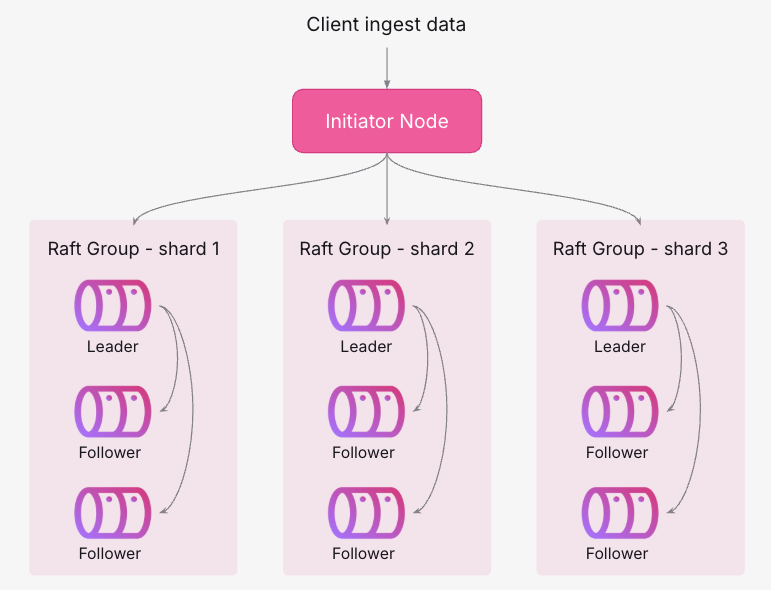
For streams with multiple shards, each shard has its own Raft group and replication is handled independently. When a batch ingest arrives at an initiator node:
- The batch is split into shard-level batches based on the stream’s sharding expression.
- Each shard batch is ingested into its corresponding shard.
- Once all shard batches have been ingested and replicated successfully, the initiator node responds to the client (for synchronous ingests).
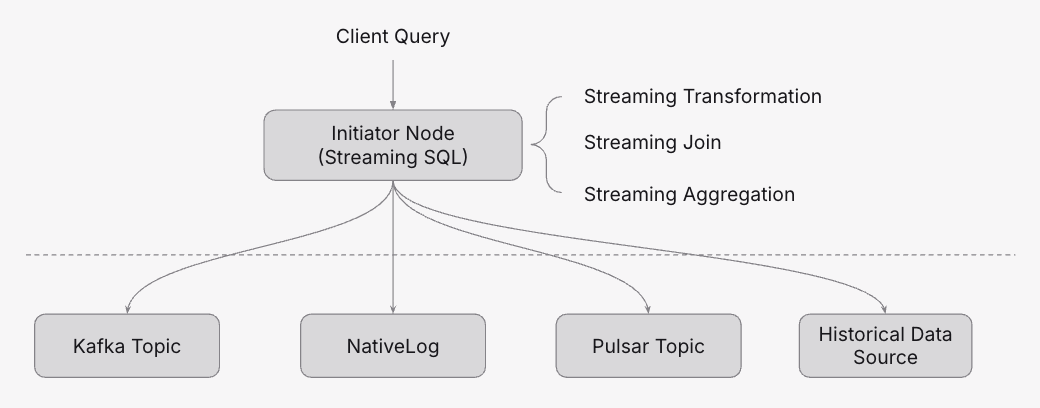
Distributed Query
Timeplus supports both streaming query, historical query and unified streaming and histroical query.
Distributed Historical Query
For distributed historical queries, Timeplus works much like traditional distributed databases:
- The initiator node creates a distributed query plan and sends subqueries to the replica peers.
- Each replica peer executes its subquery locally and, once finished, returns intermediate results to the initiator node.
- The initiator node collects all responses, merges the intermediate states, finalizes the query results, and then sends the results back to the client.
Timeplus also applies common query optimizations—such as predicate pushdown, projection pushdown, and intermediate aggregation—just like a traditional database engine.
Distributed Streaming Query
For distributed streaming queries, Timeplus continuously consumes data from various streaming sources—such as Timeplus NativeLog, Kafka topics, or Pulsar topics—and can also correlate with remote historical data sources when needed.
All data shuffling, streaming transformations, joins, and aggregations are handled on the initiator node, which then emits intermediate results to the client according to the configured emit strategy.
This design has proven to be highly efficient and performant with lowest latency since it avoids cross-node watermark coordination. Combined with hybrid joins, hybrid aggregations, query state checkpoint on cloud storage, and intelligent scheduling of streaming queries across different (compute) nodes, it ensures balanced workloads and high throughput across the cluster, and supports the majority of Timeplus use cases very well.
The following diagram depicts the streaming query flow.
Zero Replication NativeLog
When you create a stream in Timeplus, you have two main options for storing streaming data:
- Local Disk Storage (Typical MPP Style)
You can store data in NativeLog on local disks, similar to traditional MPP architectures. Data is persisted and replicated across nodes as usual. This approach works particularly well for latency-sensitive workloads and on-premises environments where cloud or shared storage is unavailable or impractical.
- Cloud Storage (S3, etc.) with Zero Replication
You can also configure the stream to store data in NativeLog on cloud storage like S3. In this setup, disk-level replication is eliminated, enabling a disk-less NativeLog. Example:
CREATE DISK s3_plain_disk disk(
type = 's3_plain',
endpoint = 'http://localhost:9000/disk/shards/',
access_key_id = 'minioadmin',
secret_access_key = 'minioadmin'
);
CREATE STREAM shared_disk_stream(i int, s string)
SETTINGS
shared_disk='s3_plain_disk',
ingest_batch_max_bytes=67108864,
ingest_batch_timeout_ms=200,
fetch_threads=1;
How It Works
The distributed ingest flow now works a bit differently internally but these differences are completely transparent to end users. The following diagram depicts this flow in details.
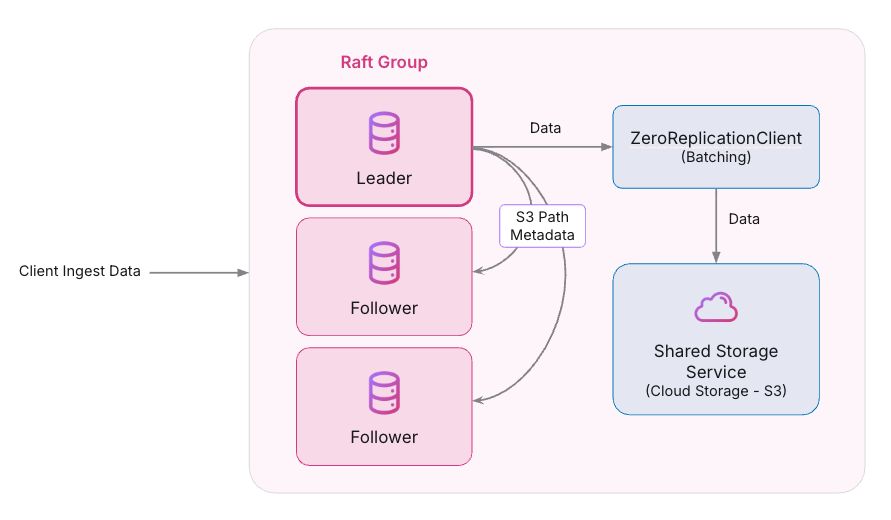
- Data is first batched in the ZeroReplicationClient.
- Once the batch reaches either the size or timeout threshold, it is uploaded to the shared storage.
- The URI/path of the file (metadata) is then replicated to the peer replicas of the NativeLog shard.
- When the file path is committed in the Raft group, the batch is considered committed.
Streaming queries over NativeLog data now work in two steps:
- Consume records from the log.
- For records referencing files in shared storage, fetch the files concurrently, decode the real data, and return the results to the client.
To reduce latency for frequently accessed data, you can enable local caching by Timeplus cached disk, allowing fetched data to be stored locally and reused across multiple queries, mitigating the overhead of repeated remote fetches.
Benefits of Shared Storage for Streaming Data
Storing streaming data on shared storage provides several advantages:
- Eliminates cross-AZ replication costs.
- Reduce local disk IOPS / bandwidth requirements
- Supports multi-master ingest, as every node can handle ingestion, send data to shared storage, and commit metadata to the NativeLog Raft group.
- Enables massive-scale streaming query processing, since most of the data can be fetched directly from shared storage and Timeplus supports auto-scale compute nodes.
Because MPP-style replication and shared-storage zero-replication are configured per stream, a Timeplus cluster can simultaneously support both architectures. This flexibility is particularly useful when different use cases have varying latency, throughput, elasticity requirements.